 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Generated Videos in Feasible Plans via World Models
Feb 02, 2026Large-scale video generative models have shown emerging capabilities as zero-shot visual planners, yet video-generated plans often violate temporal consistency and physical constraints, leading to failures when mapped to executable actions. To address this, we propose Grounding Video Plans with World Models (GVP-WM), a planning method that grounds video-generated plans into feasible action sequences using a learned action-conditioned world model. At test-time, GVP-WM first generates a video plan from initial and goal observations, then projects the video guidance onto the manifold of dynamically feasible latent trajectories via video-guided latent collocation. In particular, we formulate grounding as a goal-conditioned latent-space trajectory optimization problem that jointly optimizes latent states and actions under world-model dynamics, while preserving semantic alignment with the video-generated plan. Empirically, GVP-WM recovers feasible long-horizon plans from zero-shot image-to-video-generated and motion-blurred videos that violate physical constraints, across navigation and manipulation simulation tasks.
LearnAD: Learning Interpretable Rules for Brain Networks in Alzheimer's Disease Classification
Dec 30, 2025We introduce LearnAD, a neuro-symbolic method for predicting Alzheimer's disease from brain magnetic resonance imaging data, learning fully interpretable rules. LearnAD applies statistical models, Decision Trees, Random Forests, or GNNs to identify relevant brain connections, and then employs FastLAS to learn global rules. Our best instance outperforms Decision Trees, matches Support Vector Machine accuracy, and performs only slightly below Random Forests and GNNs trained on all features, all while remaining fully interpretable. Ablation studies show that our neuro-symbolic approach improves interpretability with comparable performance to pure statistical models. LearnAD demonstrates how symbolic learning can deepen our understanding of GNN behaviour in clinical neuroscience.
Beyond Fixed Tasks: Unsupervised Environment Design for Task-Level Pairs
Nov 16, 2025Training general agents to follow complex instructions (tasks) in intricate environments (levels) remains a core challenge in reinforcement learning. Random sampling of task-level pairs often produces unsolvable combinations, highlighting the need to co-design tasks and levels. While unsupervised environment design (UED) has proven effective at automatically designing level curricula, prior work has only considered a fixed task. We present ATLAS (Aligning Tasks and Levels for Autocurricula of Specifications), a novel method that generates joint autocurricula over tasks and levels. Our approach builds upon UED to automatically produce solvable yet challenging task-level pairs for policy training. To evaluate ATLAS and drive progress in the field, we introduce an evaluation suite that models tasks as reward machines in Minigrid levels. Experiments demonstrate that ATLAS vastly outperforms random sampling approaches, particularly when sampling solvable pairs is unlikely. We further show that mutations leveraging the structure of both tasks and levels accelerate convergence to performant policies.
Red-Bandit: Test-Time Adaptation for LLM Red-Teaming via Bandit-Guided LoRA Experts
Oct 08, 2025Automated red-teaming has emerged as a scalable approach for auditing Large Language Models (LLMs) prior to deployment, yet existing approaches lack mechanisms to efficiently adapt to model-specific vulnerabilities at inference. We introduce Red-Bandit, a red-teaming framework that adapts online to identify and exploit model failure modes under distinct attack styles (e.g., manipulation, slang). Red-Bandit post-trains a set of parameter-efficient LoRA experts, each specialized for a particular attack style, using reinforcement learning that rewards the generation of unsafe prompts via a rule-based safety model. At inference, a multi-armed bandit policy dynamically selects among these attack-style experts based on the target model's response safety, balancing exploration and exploitation. Red-Bandit achieves state-of-the-art results on AdvBench under sufficient exploration (ASR@10), while producing more human-readable prompts (lower perplexity). Moreover, Red-Bandit's bandit policy serves as a diagnostic tool for uncovering model-specific vulnerabilities by indicating which attack styles most effectively elicit unsafe behaviors.
Test-Time Adaptation for Generalizable Task Progress Estimation
Jun 11, 2025We propose a test-time adaptation method that enables a progress estimation model to adapt online to the visual and temporal context of test trajectories by optimizing a learned self-supervised objective. To this end, we introduce a gradient-based meta-learning strategy to train the model on expert visual trajectories and their natural language task descriptions, such that test-time adaptation improves progress estimation relying on semantic content over temporal order. Our test-time adaptation method generalizes from a single training environment to diverse out-of-distribution tasks, environments, and embodiments, outperforming the state-of-the-art in-context learning approach using autoregressive vision-language models.
An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Mar 07, 2025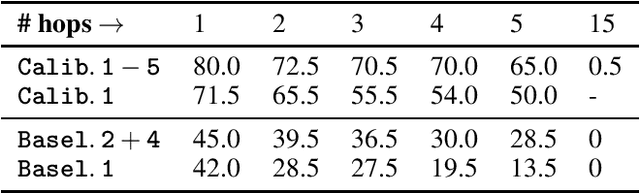

In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM's performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
$\texttt{SEM-CTRL}$: Semantically Controlled Decoding
Mar 03, 2025Ensuring both syntactic and semantic correctness in Large Language Model (LLM) outputs remains a significant challenge, despite being critical for real-world deployment. In this paper, we introduce $\texttt{SEM-CTRL}$, a unified approach that enforces rich context-sensitive constraints and task- and instance-specific semantics directly on an LLM decoder. Our approach integrates token-level MCTS, which is guided by specific syntactic and semantic constraints. The constraints over the desired outputs are expressed using Answer Set Grammars -- a logic-based formalism that generalizes context-sensitive grammars while incorporating background knowledge to represent task-specific semantics. We show that our approach guarantees correct completions for any off-the-shelf LLM without the need for fine-tuning. We evaluate $\texttt{SEM-CTRL}$ on a range of tasks, including synthetic grammar synthesis, combinatorial reasoning, and planning. Our results demonstrate that $\texttt{SEM-CTRL}$ allows small pre-trained LLMs to efficiently outperform larger variants and state-of-the-art reasoning models (e.g., o1-preview) while simultaneously guaranteeing solution correctness.
Neural DNF-MT: A Neuro-symbolic Approach for Learning Interpretable and Editable Policies
Jan 07, 2025Although deep reinforcement learning has been shown to be effective, the model's black-box nature presents barriers to direct policy interpretation. To address this problem, we propose a neuro-symbolic approach called neural DNF-MT for end-to-end policy learning. The differentiable nature of the neural DNF-MT model enables the use of deep actor-critic algorithms for training. At the same time, its architecture is designed so that trained models can be directly translated into interpretable policies expressed as standard (bivalent or probabilistic) logic programs. Moreover, additional layers can be included to extract abstract features from complex observations, acting as a form of predicate invention. The logic representations are highly interpretable, and we show how the bivalent representations of deterministic policies can be edited and incorporated back into a neural model, facilitating manual intervention and adaptation of learned policies. We evaluate our approach on a range of tasks requiring learning deterministic or stochastic behaviours from various forms of observations. Our empirical results show that our neural DNF-MT model performs at the level of competing black-box methods whilst providing interpretable policies.
$\texttt{FORM}$: Learning Expressive and Transferable First-Order Logic Reward Machines
Dec 31, 2024Reward machines (RMs) are an effective approach for addressing non-Markovian rewards in reinforcement learning (RL) through finite-state machines. Traditional RMs, which label edges with propositional logic formulae, inherit the limited expressivity of propositional logic. This limitation hinders the learnability and transferability of RMs since complex tasks will require numerous states and edges. To overcome these challenges, we propose First-Order Reward Machines ($\texttt{FORM}$s), which use first-order logic to label edges, resulting in more compact and transferable RMs. We introduce a novel method for $\textbf{learning}$ $\texttt{FORM}$s and a multi-agent formulation for $\textbf{exploiting}$ them and facilitate their transferability, where multiple agents collaboratively learn policies for a shared $\texttt{FORM}$. Our experimental results demonstrate the scalability of $\texttt{FORM}$s with respect to traditional RMs. Specifically, we show that $\texttt{FORM}$s can be effectively learnt for tasks where traditional RM learning approaches fail. We also show significant improvements in learning speed and task transferability thanks to the multi-agent learning framework and the abstraction provided by the first-order language.
Transformers Use Causal World Models in Maze-Solving Tasks
Dec 16, 2024



Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain's structure, they are commonly referred to as ``World Models'' (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model's residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.